The popularization of Text-to-Image (T2I) diffusion models enables the generation of high-quality images from text descriptions. However, generating diverse customized images with reference visual attributes remains challenging. This work focuses on personalizing T2I diffusion models at a more abstract concept or category level, adapting commonalities from a set of reference images while creating new instances with sufficient variations. We introduce a solution that allows a pretrained T2I diffusion model to learn a set of soft prompts, enabling the generation of novel images by sampling prompts from the learned distribution. These prompts offer text-guided editing capabilities and additional flexibility in controlling variation and mixing between multiple distributions. We also show the adaptability of the learned prompt distribution to other tasks, such as text-to-3D. Finally we demonstrate effectiveness of our approach through quantitative analysis including automatic evaluation and human assessment.
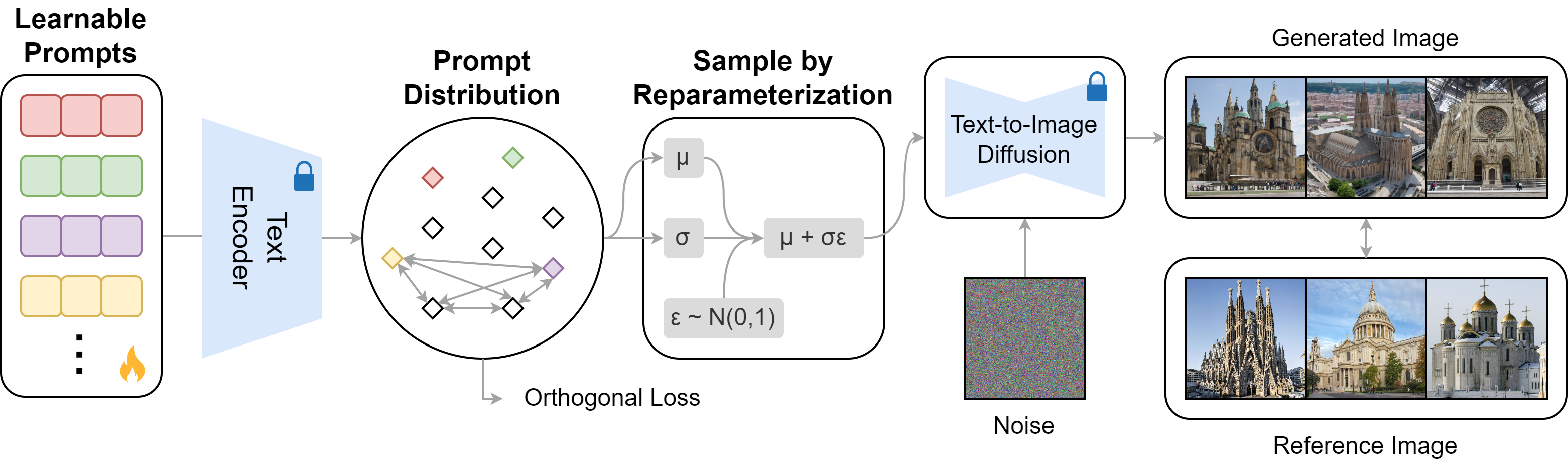
We keep a set of K learnable soft prompts and model a distribution of them at the CLIP text encoder feature space. Only prompts are learnable, CLIP encoder and the T2I diffusion model are all fixed. We use a reparameterization trick to sample from the prompt distribution and update the learnable prompts through backpropagation. The training objective is to make the generated images aligns with the reference image. An additional orthogonal loss is incorporated to promote differentiation among learnable prompts. For inference, we similarly sample from the prompt distribution at text feature space to guide the pretrained T2I generation.
Comparison with Other Methods

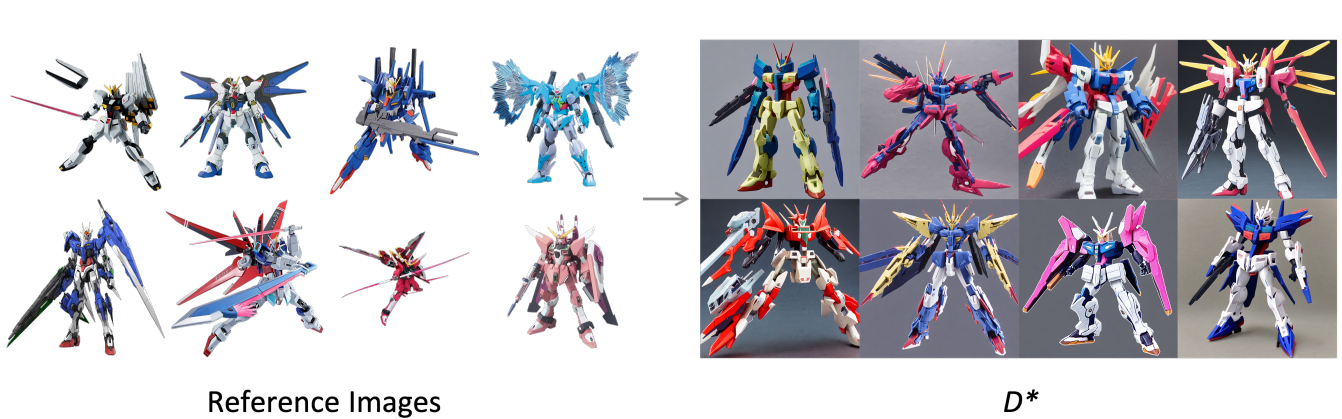
Given a set of training images (typically 5-20, we only show 4 here), we compare generation results with other existing methods. We use Stable Diffusion version 2.1 for all methods. As can be seen on the bottom row, our method is able to generate more diverse and coherent images.

Reference Images

Generated Images
More results of generated image using reference images. Images in the left columns are reference images, and images in the right columns are generated images.
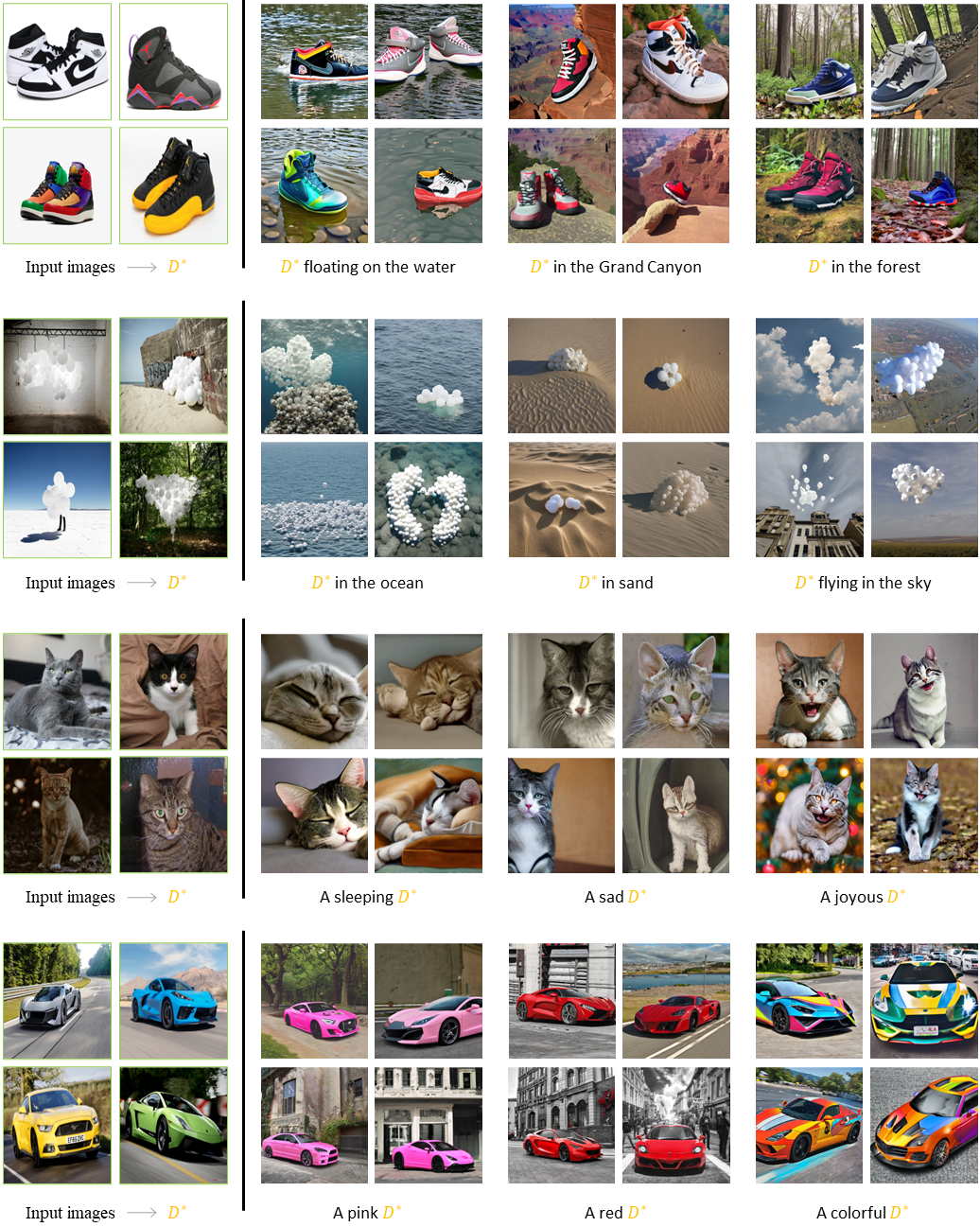
Results on text-editability of our methods. Left column shows samples of reference images, right columns are generated results with corresponding prompts.
3D generation results by learning a prompt distribution over the reference images and then inference using MVDream (without extra texts).
3D generation results by learning a prompt distribution over the reference images and then inference with text-guided editing using MVDream.


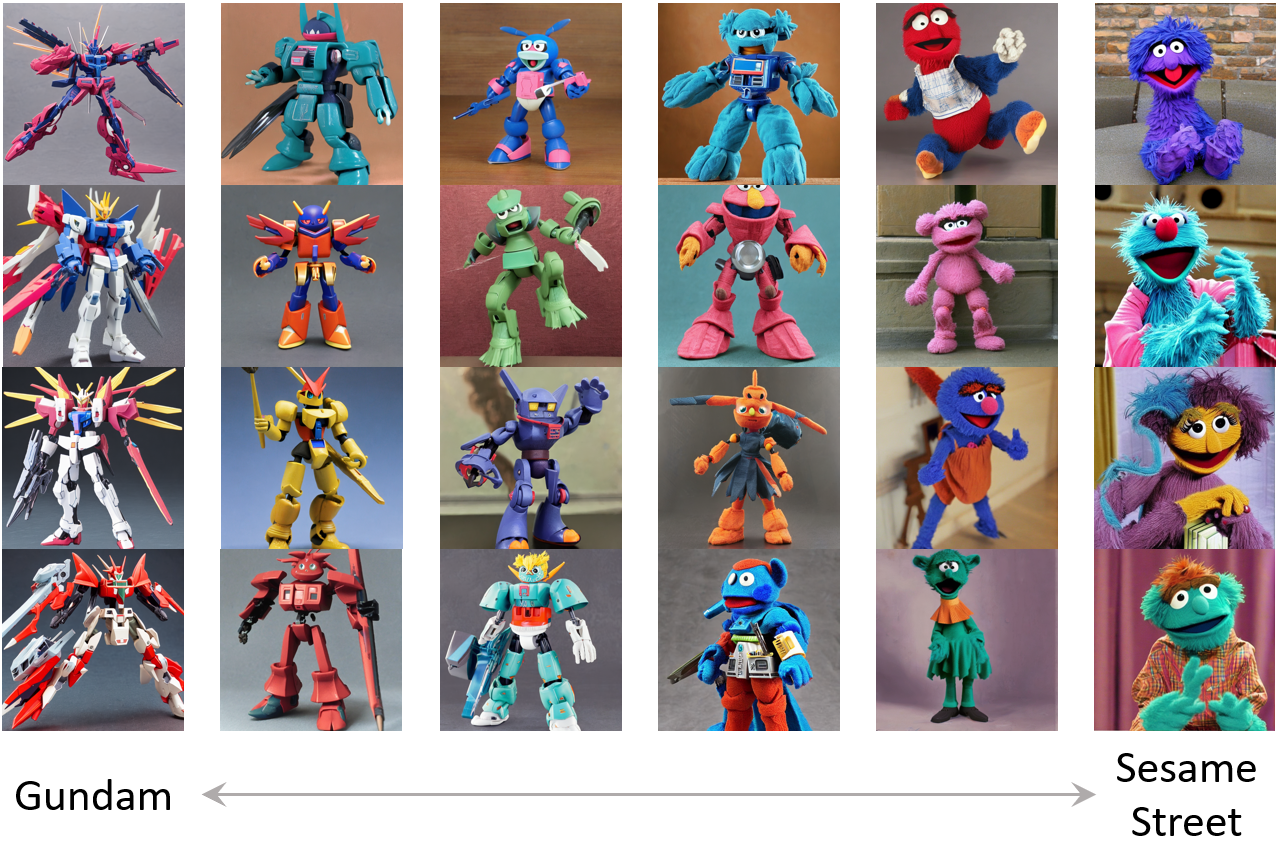
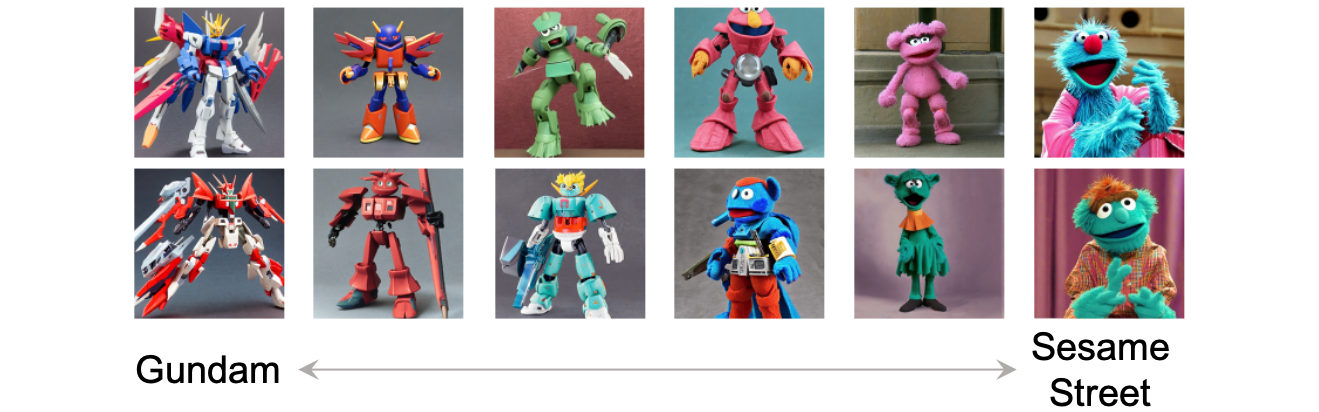
Composition of prompt distributions using linear interpolation between two sets of images. Mixing ratio changes linearly from left to right. The middle columns show mixtures of two sets.



Effect of scaling the variance of a learned prompt distribution, by multiplying variance with a scalar γ. Image diversity increases as the scaling factor γ increases.

Comparison between training images generated using our method and image generated using solely class names as text prompts. For each group of two rows, the top row shows samples of our generated training images, and the bottom row shows the training images generated using class names as text prompts.