Full list on Google Scholar
$*$ = equal contribution
$\dagger$ = equal supervision
-
Kirin: Animal Motion Generation from In-the-Wild Video
In Submission
TL;DR
Animal motion dataset with aligned video-text-motion tuple, and an end-to-end framework that generates animated 3D animal mesh from text and image input.
-
Web-Scale Collection of Video Data for 4D Animal Reconstruction
NeurIPS 2025 Datasets and Benchmarks
TL;DR
A framework for obtaining large-scale 4D animal assets from zero, including a data engine that automatically scrape and process online video, and an animal reconstruction method adapted for sequence reconstruction, as well as benchmark evaluation set for 4D animal reconstruction task.
-
DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models
ICLR 2025
TL;DR
A novel, simple approach to learn a semantic distribution of images that enables diverse personalized image and 3D generation with flexible variations and editing capabilities.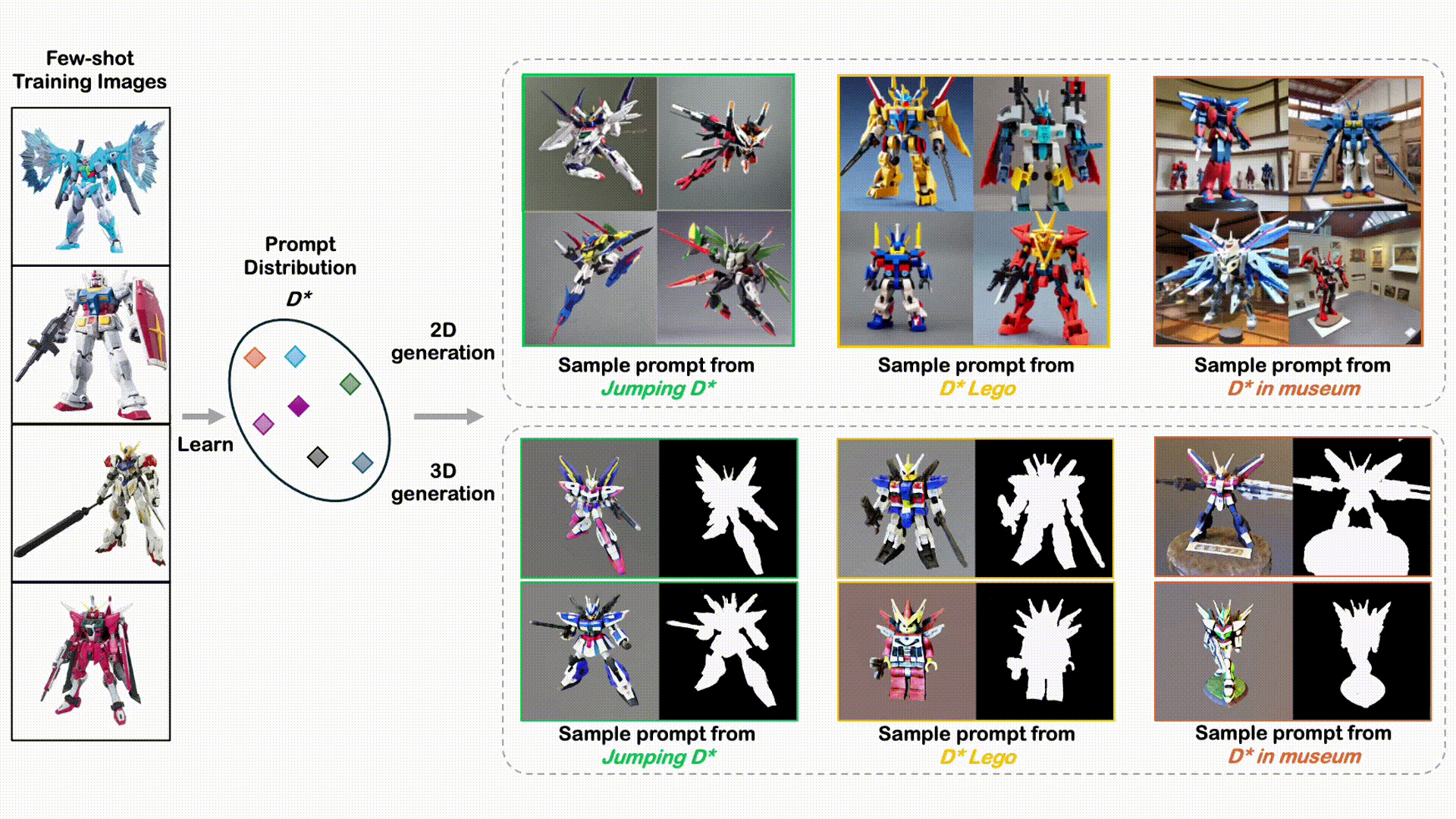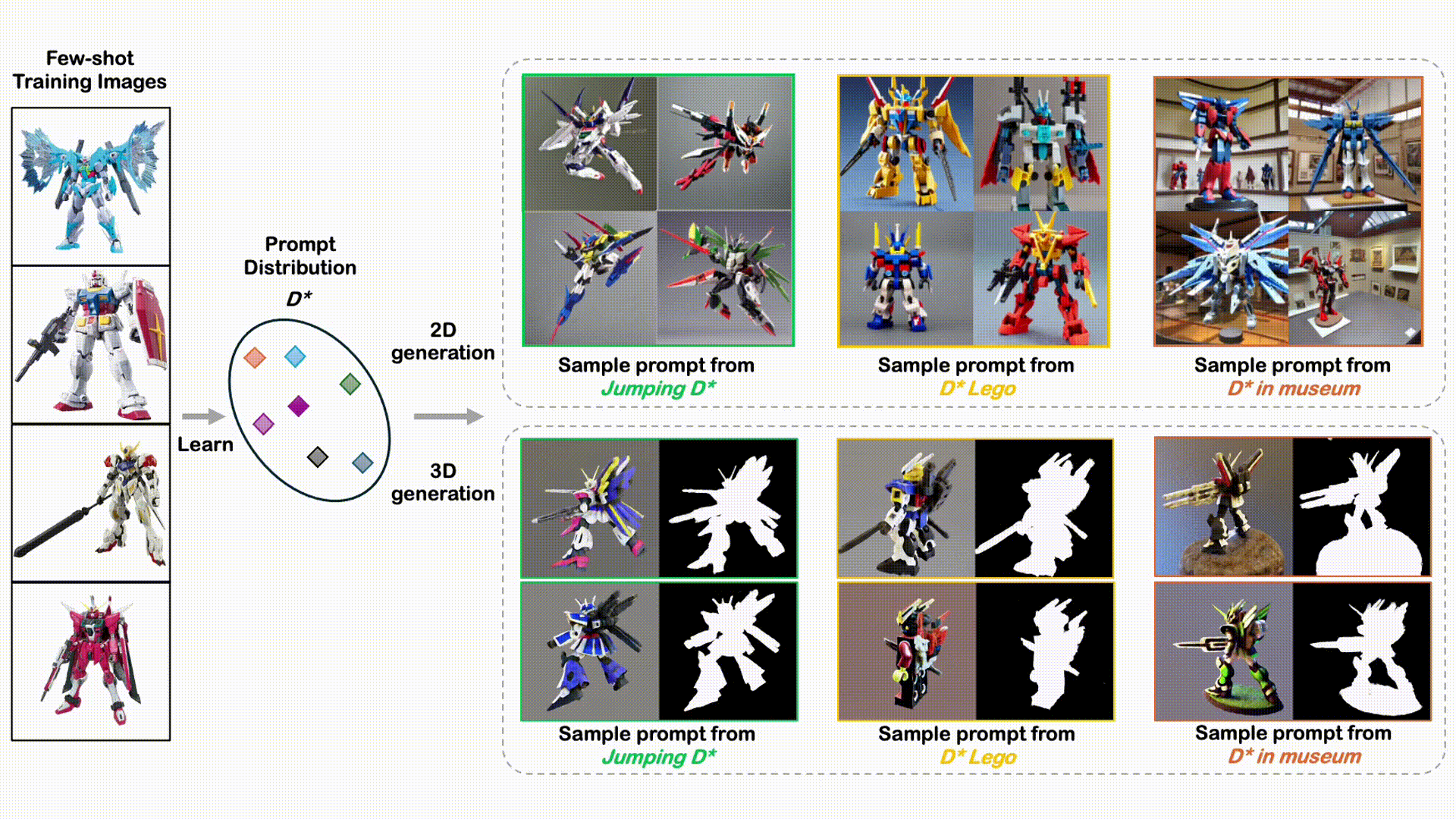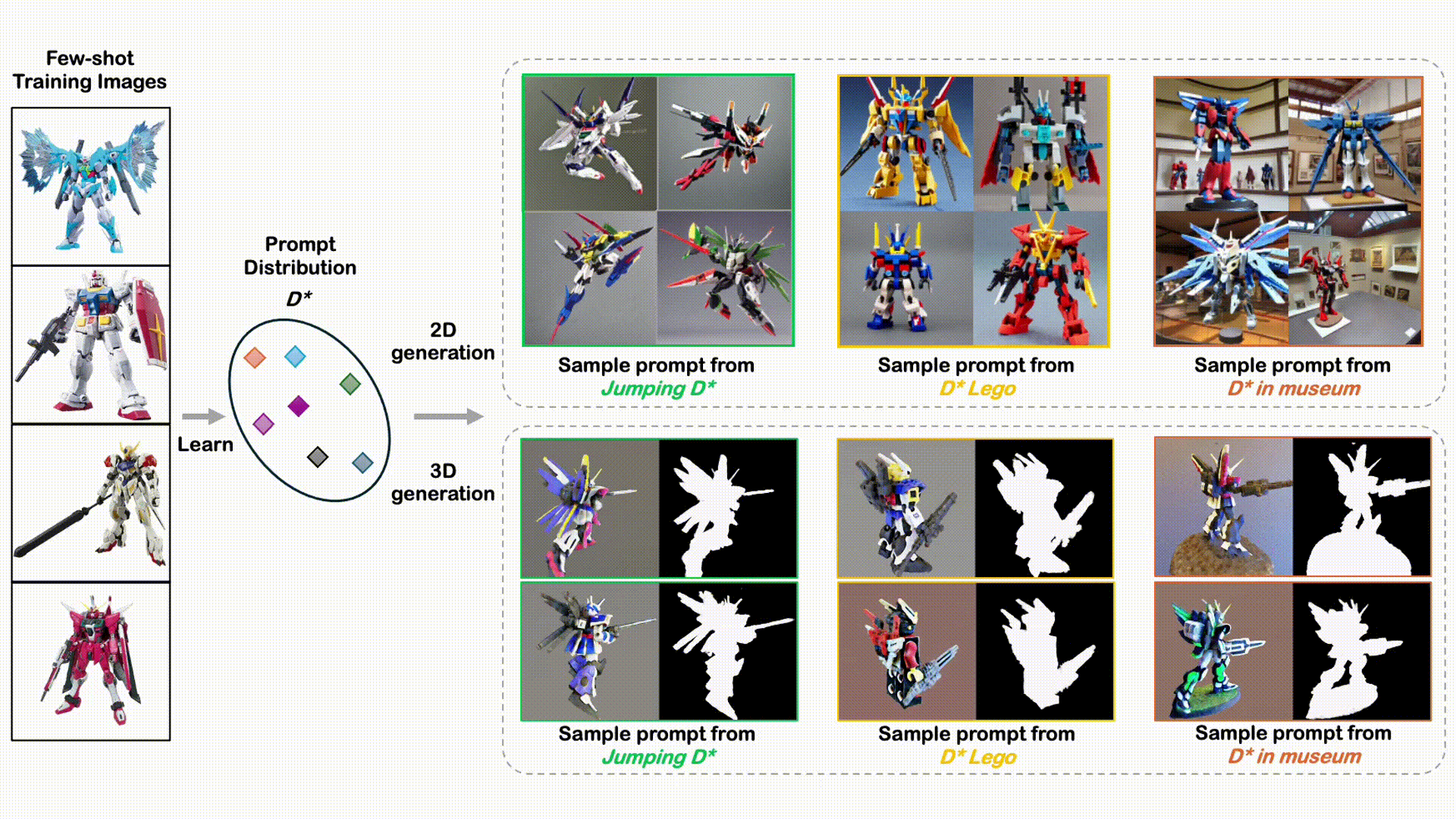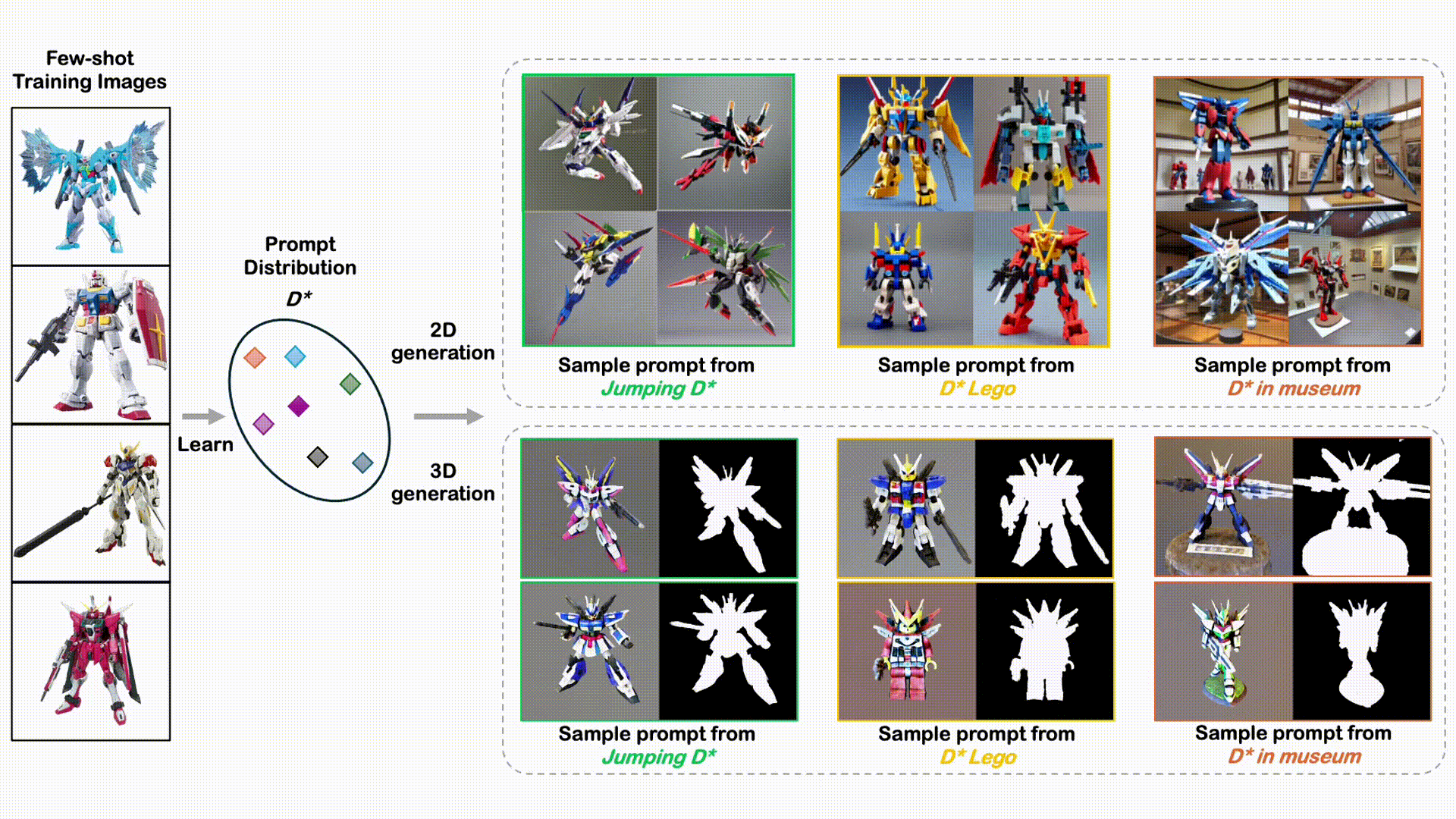
-
Probabilistic Prompt Distribution Learning for Animal Pose Estimation
CVPR 2025
TL;DR
A probabilistic prompt-learning approach for multi-species animal pose estimation using diverse textual representations and cross-modal fusion to handle large data variances, achieving state-of-the-art animal pose estimation results.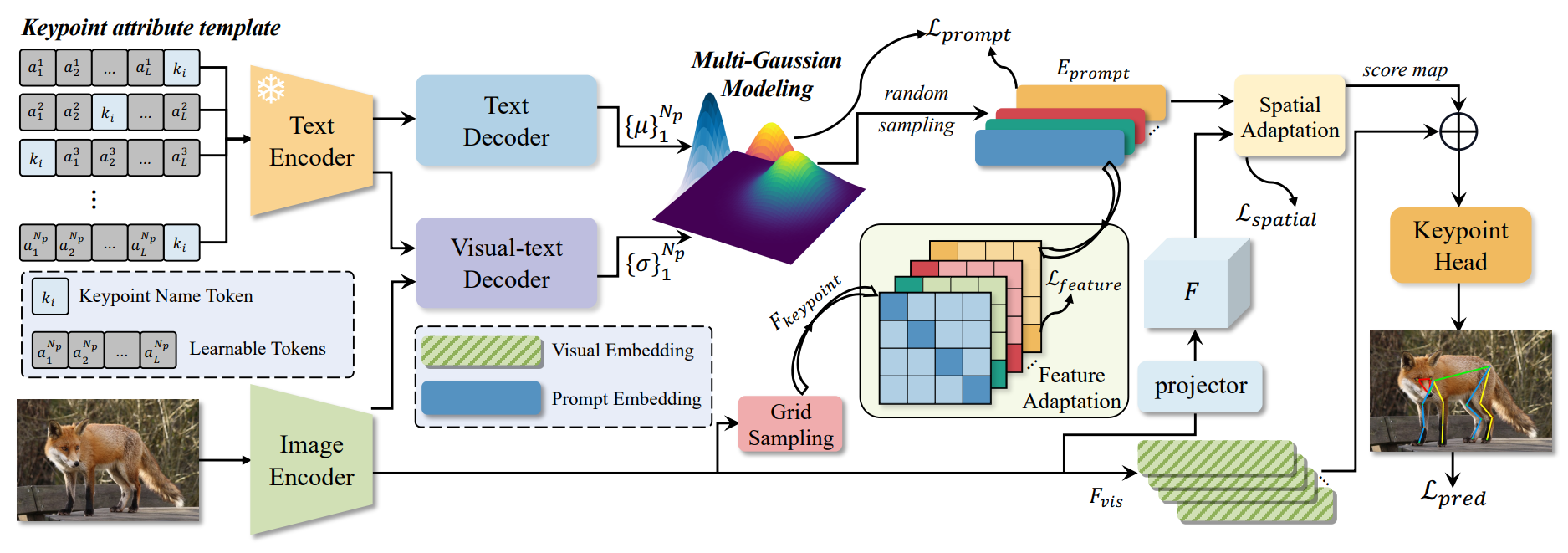
-
Benchmark Dataset for Radiology Report Generation with Instructions and Contexts
Submitted to MICCAI 2025
TL;DR
New radiology report generation tasks, data generation pipeline, and dataset in real-world clinical setting with medical contexts. A novel baseline model architecture to adapt general domain visual LLM to medical domain and report generation task with context.
-
Self-Supervised 3-D Action Recognition by Contrasting Context-Enhanced Action Embeddings
IEEE Transactions on Computational Social Systems
TL;DR
Solving 3D action recognition task by new approah that uses graph-based encoder and GraphGRU with a context-aware topology attention mechanism.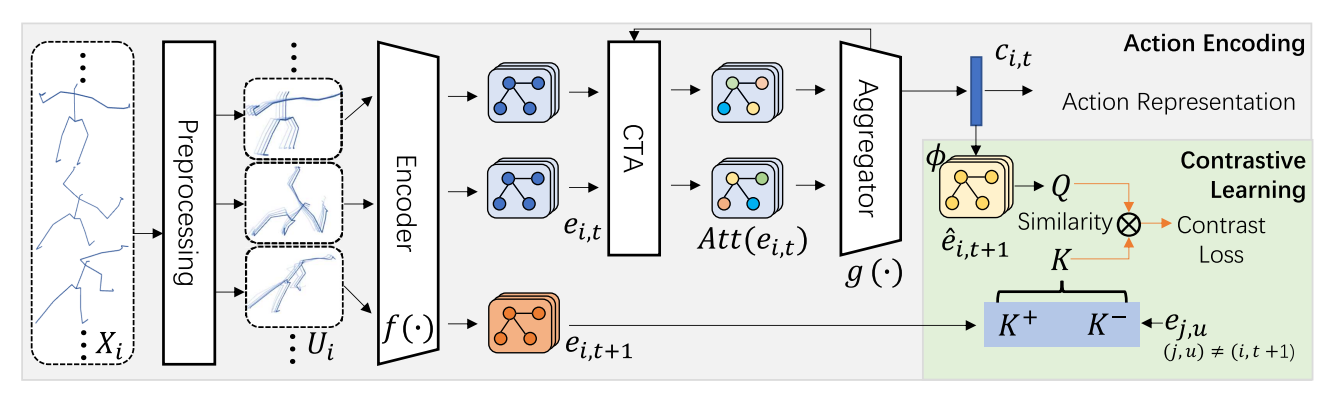
-
Beyond generation: Harnessing Text to Image Models for Object Detection and Segmentation
arXiv preprint 2023
TL;DR
A method for generating detection and segmentation training data using text-to-image synthesis and a copy-and-paste scheme, achieving performance comparable to real data alone and performing even better when combined with real data, while excelling in zero-shot and out-of-distribution scenarios.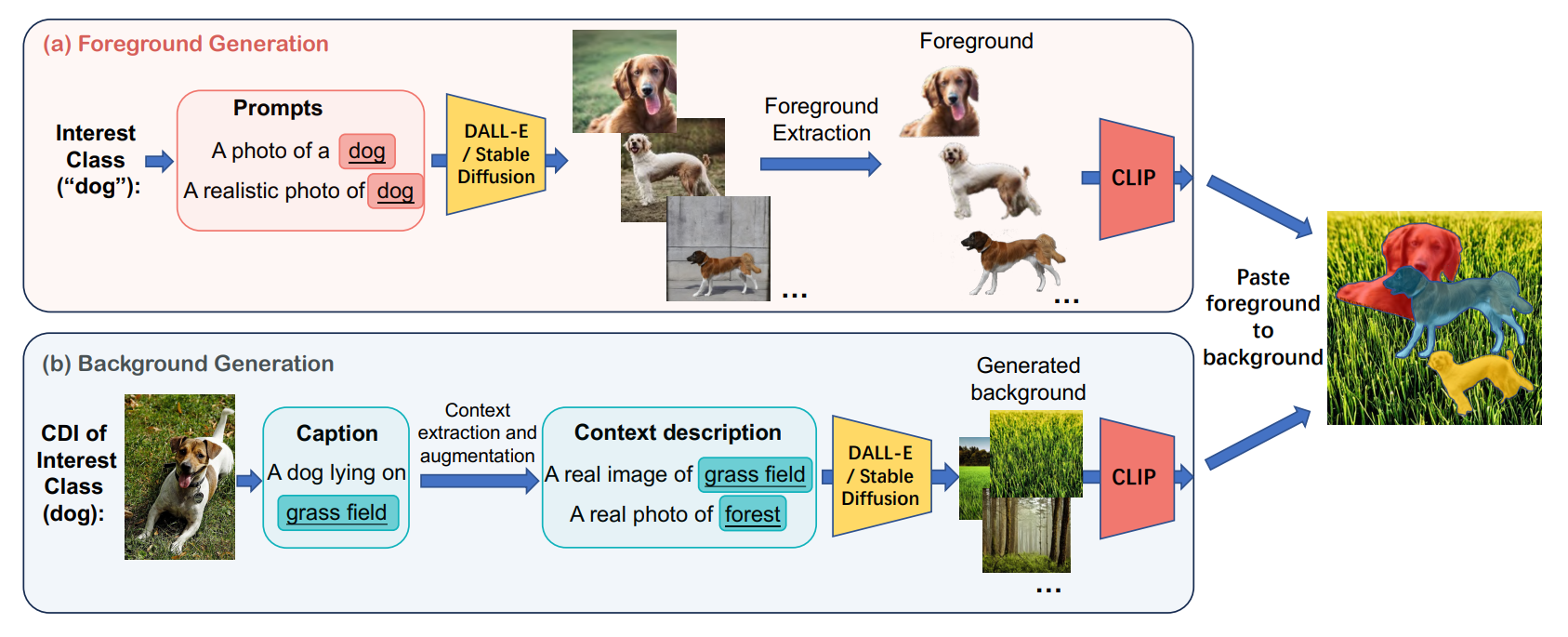
-
EM-Paste: EM-guided Cut-Paste with DALL-E Augmentation for Image-level Weakly Supervised Instance Segmentation
arXiv preprint 2022
TL;DR
An EM-guided segment selection and cut-paste approach for weakly-supervised instance segmentation using only image-level supervision. By refining object masks, generating context-aware backgrounds, and compositing these into a pseudo-labeled dataset, EM-Paste achieves state-of-the-art results on PASCAL VOC and COCO, outperforming baselines and addressing long-tail class augmentation.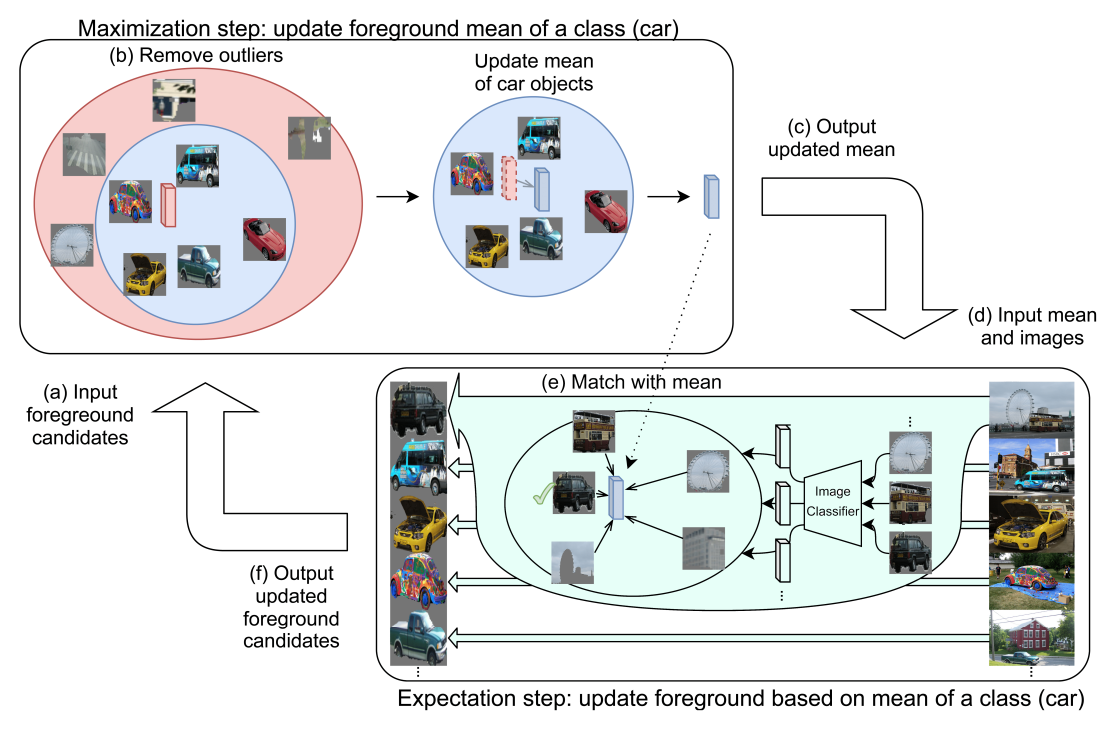
-
Progressive Motion Coherence for Remote Sensing Image Matching
IEEE Transactions on Geoscience and Remote Sensing Volume 60
TL;DR
A feature-based remote sensing image matching method that uses novel coherence constraints for robustness to image degradations and large rotations.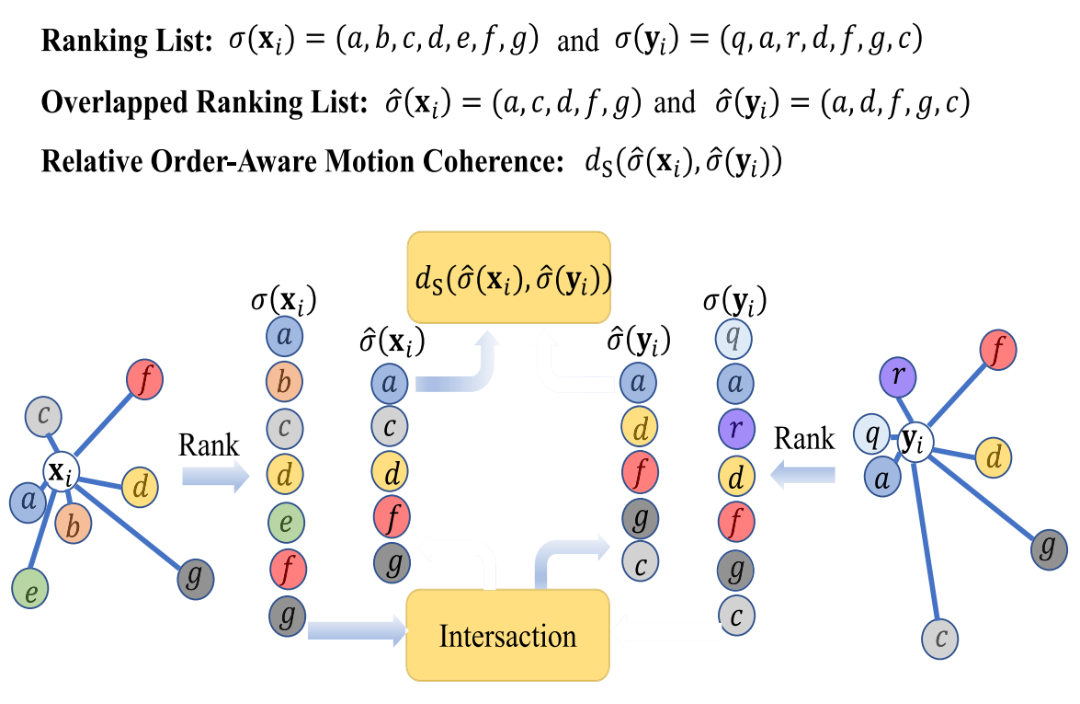
-
Rectified Neighborhood Construction for Robust Feature Matching With Heavy Outliers
IEEE Geoscience and Remote Sensing Letters Volume 19
TL;DR
A rectified neighborhood construction strategy to improve local consistency-based feature matching by mitigating the impact of outliers and adaptively estimating parameters.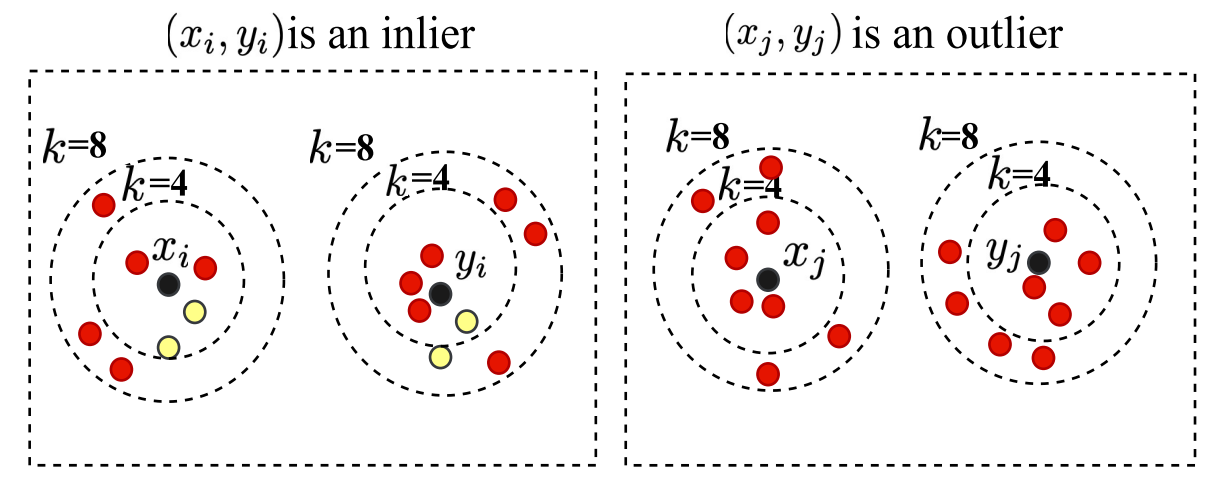
-
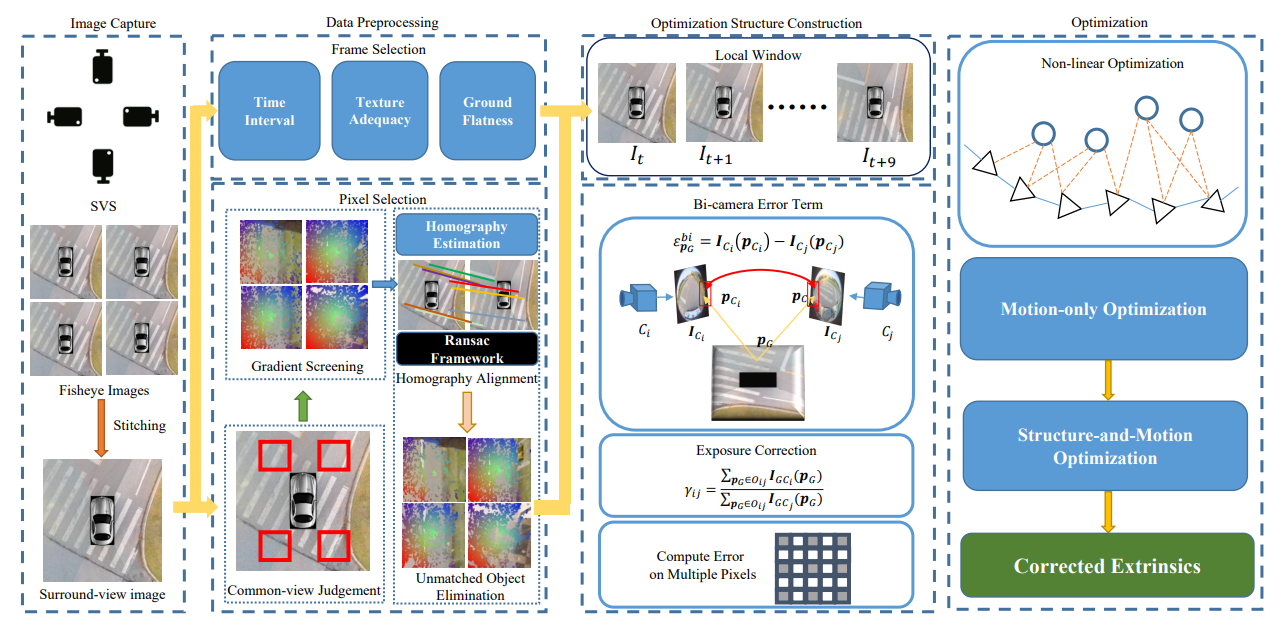
Extrinsic Self-calibration of the Surround-view System: A Weakly Supervised Approach
IEEE Transactions on Multimedia Volume 25
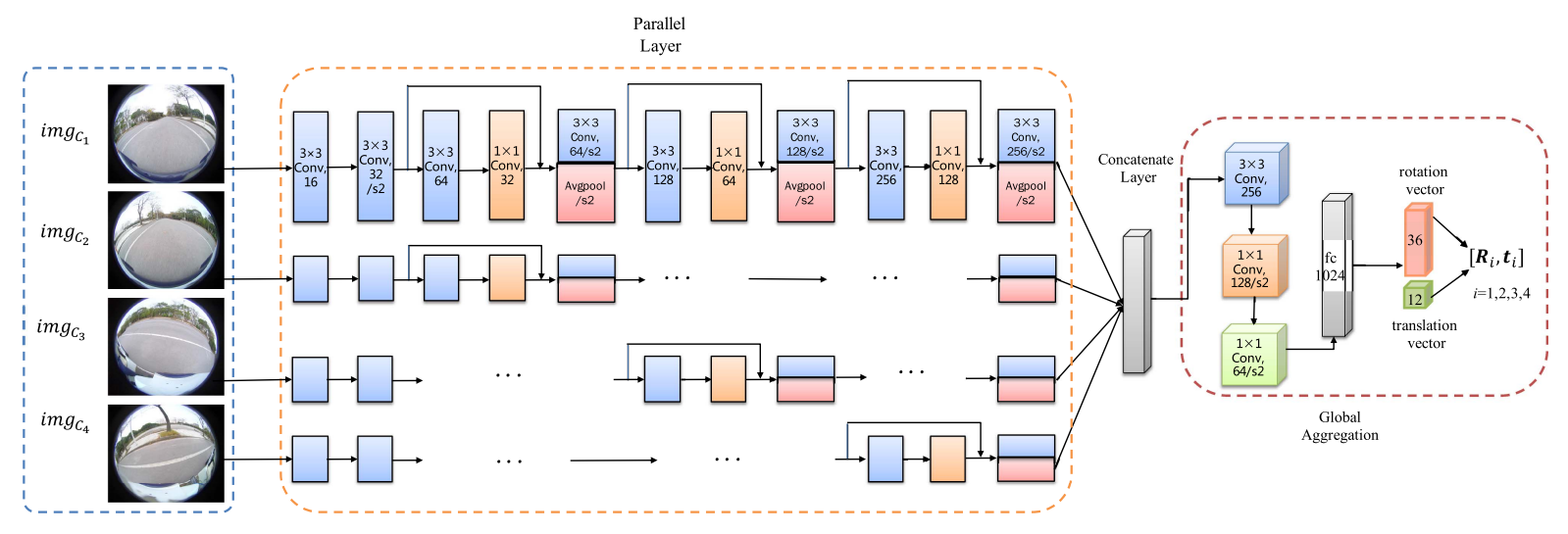
-
Scene Text Image Super-Resolution via Parallelly Contextual Attention Network
ACM Multimedia 2021
TL;DR
A network architecture that reconstructs high-frequency information and adaptively captures horizontal and vertical sequence-dependent features for text super-resolution.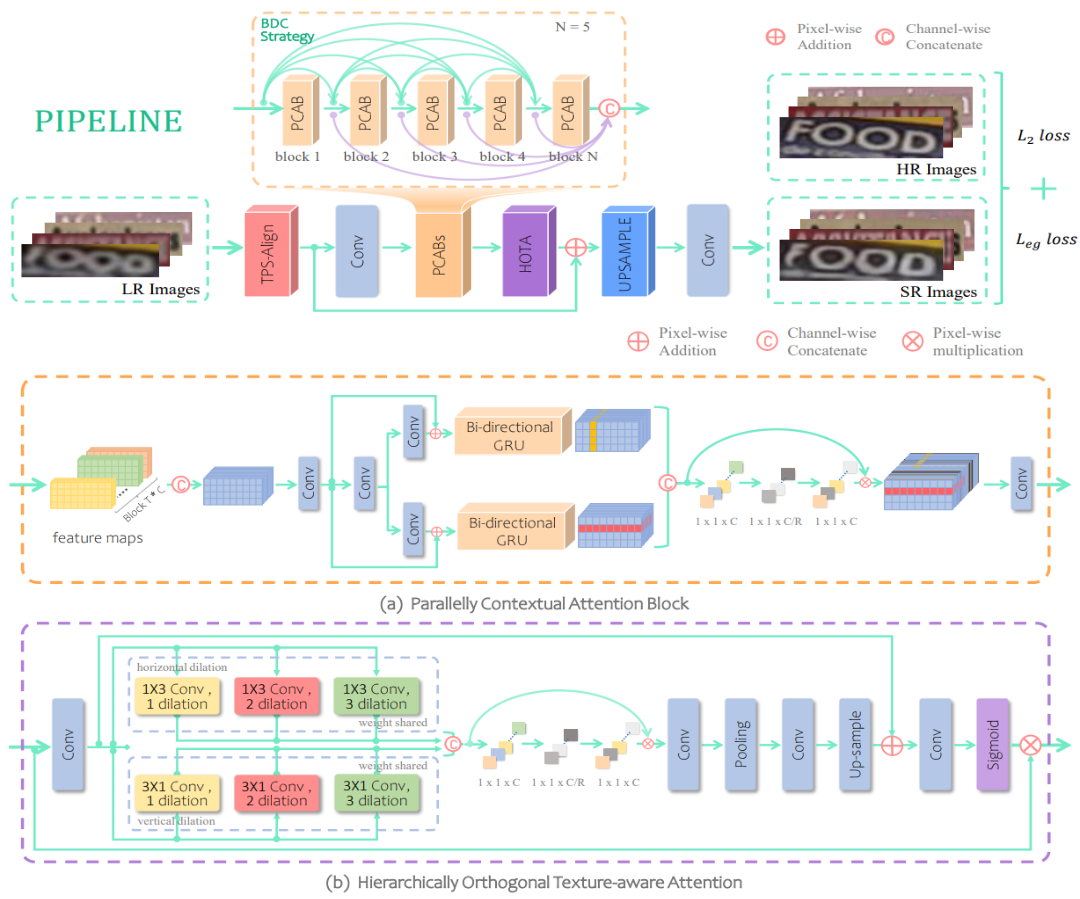
-
ROECS: A Robust Semi-direct Pipeline Towards Online Extrinsics Correction of the Surround-view System
ACM Multimedia 2021